Spring Data Management in Spring Professional Certification (16%).
What is the difference between checked and unchecked exceptions
- Checked exceptions: Java compiler requires to handle. E.g.,
Exception - Unchecked exceptions: compiler not require to declare. E.g.,
RuntimeException.
Why does Spring prefer unchecked exceptions
- Checked exceptions reqires handling, result in cluttered code and unnecessary coupling.
- Unchecked exceptions are non-recoverable exceptions, should not let developer to handle. E.g., when
SQLExceptionhappens, nothing you can do.
What is the data access exception hierarchy
Each data access technology has its own exception types, such as
- SQLException for direct JDBC access,
- HibernateException used by native Hibernate, or
- EntityException used by JPA
What Spring does is to handle technology‐specific exceptions and translate them into its own exception hierarchy. The hierarchy is to isolate developers from the particulars of JDBC data access APIs from different vendors.
Spring’s DataAccessException
- It is an abstract class,
- It is the root exception.
- Its sub-classes are unchecked exceptions.
Spring data access exception family has three main branches:
org.springframework.dao.NonTransientDataAccessException- non-transient exceptions,
- which means that retrying the operation will fail unless the originating cause is fixed.
- The most obvious example here is searching for an object that does not exist.
RecoverableDataAccessException- when a previously failed operation might succeed if some recovery steps are performed,
- usually closing the current connection and using a new one.
- E.g., a temporary network hiccup
springframework.dao.TransientDataAccessException.- transient exception,
- which means that retrying the operation might succeed without any intervention.
- These are concurrency or latency exceptions.
- For example, when the database becomes unavailable because of a bad network connection in the middle of the execution of a query, an exception of type
QueryTimeoutExceptionis thrown. The developer can treat this exception by retrying the query.
How do you configure a DataSource in Spring
Spring obtains a connection to the database through a DataSource.
DataSource VS Connection: DataSource provides and manages Connections.
Spring offers several options for configuring data-source beans, including:
-
Data sources that are defined by a JDBC driver
-
Data sources that are looked up by JNDI.
-
Data sources that connection pool implementation.
-
An embedded database runs as part of your application instead of as a separate database server that your application connects to.
Orders of choice
- The preferred way Using JNDI data sources
- they can be managed completely external to the application, allowing the application to ask for a data source when it’s ready to access the database.
- Moreover, data sources managed in an application server are often pooled for greater performance and can be hot-swapped by system administrators
-
In SpringBoot, obtain a DataSource from JNDI
spring.datasource.jndi-name=java:jdbc/customers@Bean public JndiObjectFactoryBean dataSource() { JndiObjectFactoryBean jndiObjectFB = new JndiObjectFactoryBean(); jndiObjectFB.setJndiName("jdbc/demodb"); jndiObjectFB.setResourceRef(true); jndiObjectFB.setProxyInterface(javax.sql.DataSource.class); return jndiObjectFB; }
- The next best Using a pooled data source
- Spring doesn’t provide a pooled data source
- Apache Commons DBCP:
BasicDataSource - c3p0
- BoneCP
-
In SpringBoot, configure the datasource
spring.datasource.hikari.maximum-pool-size=5 spring.datasource.hikari.minimum-idle=2 spring.datasource.hikari.leak-detection-threshold=20000@Bean public BasicDataSource dataSource() { BasicDataSource ds = new BasicDataSource(); ds.setDriverClassName("org.h2.Driver"); ds.setUrl("jdbc:h2:tcp://localhost/~/demodb"); ds.setUsername("sa"); ds.setPassword(""); ds.setInitialSize(5); ds.setMaxActive(10); return ds; }
-
simplest Using JDBC driver-based data sources
The simplest data source you can configure in Spring is one that’s defined through a JDBC driver. Spring offers three such data-source classes to choose from:
DriverManagerDataSource.- the simplest implementation of a DataSource,
- Returns a new connection every time.
- Connections are not pooled.
- it performs poorly when multiple requests for a connection are made
- unsuitable for anything other than testing.
- capable of supporting multiple threads, they incur a performance cost for creating a new connection each time a connection is requested.
@Bean public DataSource dataSource() { DriverManagerDataSource ds = new DriverManagerDataSource(); ds.setDriverClassName("org.h2.Driver"); ds.setUrl("jdbc:h2:tcp://localhost/~/spitter"); ds.setUsername("sa"); ds.setPassword(""); return ds; }SimpleDriverDataSource- Similar as
DriverManagerDataSource - capable of supporting multiple threads, they incur a performance cost for creating a new connection each time a connection is requested.
- except that it works with the JDBC driver directly
- Similar as
SingleConnectionDataSource- Returns the same connection every time a connection is requested.
- wraps a single Connection that is not closed after each use
- Obviously, this is not multi-threading capable.
- It isn’t exactly a pooled data source, you can think of it as a data source with a pool of exactly one connection.
-
Using an embedded data source
An embedded database runs as part of your application instead of as a separate database server that your application connects to.
- it’s not very useful in production settings,
- an embedded database is a perfect choice for development and testing purposes. That’s because it allows you to populate your database with test data that’s reset every time you restart your application or run your tests.
- Spring’s jdbc namespace makes configuring an embedded database simple, with XML config.
- In SpringBoot, Spring Boot detects that you have the H2 database library in your application’s classpath, it will automatically configure an embedded H2 database.
- With Java configuration, you can use
EmbeddedDatabaseBuilderto construct the DataSource:
@Bean public DataSource dataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.H2) .addScript("classpath:schema.sql") .addScript("classpath:test-data.sql") .build(); } - Using profiles, the data source is chosen at runtime, based on which profile is active.
- the embedded database is created if and only if the development profile is active.
- Similarly, the DBCP BasicDataSource is created if and only if the qa profile is active.
- And the data source is retrieved from JNDI if and only if the production profile is active.
Which bean is very useful for development/test databases
The embedded data source.
- It runs as part of application instead of being a standalone element.
- it allows you to populate your database with test data that’s reset every time you restart your application or run your tests.
- Spring Boot can auto-configure embedded H2, HSQL, and Derby databases. You need not provide any connection URLs. You need only include a build dependency to the embedded database that you want to use.
-
Spring Boot automatically creates the schema of an embedded DataSource. This behaviour can be customized by using the
spring.datasource.initialization-modeproperty. For instance, if you want to always initialize the DataSource regardless of its type:spring.datasource.initialization-mode=always
What is the Template design pattern? What is the JDBC template
Template design pattern
A template method defines the skeleton of a process.
At certain points, the process delegates its work to a subclass to fill in some implementation-specific details. This is the variable part of the process.
Spring separates the fixed and variable parts of the data-access process into two distinct classes: templates and callbacks.
- Templates manage the fixed of data access
- establishing connection
- handling transactions
- handling excetions
- clean up and release resource
- your custom data-access code is handled in callbacks
- creating statements,
- binding parameters, and
- marshaling result sets
What is the JDBC template
The Spring JdbcTemplate simplifies the use of JDBC by implementing common workflows for
- querying,
- updating,
- statement execution etc.
Benefits are:
- Simplification: reduces boilerplate code for operations
- Handle exceptions
- Translates Exception from different vendors, e.g.,
DataAccessException - Avoids common mistake: release connections
- Allows customization, it’s template design pattern
- Thread safe
Spring comes with three template classes to choose from:
- JdbcTemplate
- NamedParameterJdbcTemplate
- SimpleJdbcTemplate (deprecated)
JdbcTemplate:
-
JdbcTemplate works with queries that specify parameters using the
'?'placeholder. -
Use
queryForObjectwhen it is expected that execution of the query will return a single result. -
Use
RowMapper<T>when each row of the ResultSet maps to a domain object. -
Use
RowCallbackHandlerwhen no value should be returned. -
Use
ResultSetExtractor<T>when multiple rows in the ResultSet map to a single object. -
initialize JdbcTemplate
The general practice is to initialize JdbcTemplate within the setDataSource method so that once the data source is injected by Spring, JdbcTemplate will also be initialized and ready for use.
Once configured, JdbcTemplate is thread-safe. That means you can also choose to initialize a single instance of JdbcTemplate in Spring’s configuration and have it injected into all DAO beans.
@Configuration public class DemoJdbcConfig { @Bean public DataSource dataSource() { return new DataSource(); } @Bean public JdbcTemplate jdbcTemplate(){ JdbcTemplate jdbcTemplate = new JdbcTemplate(); jdbcTemplate.setDataSource(dataSource()); return jdbcTemplate; } } @Bean public SingerDao singerDao() { JdbcSingerDao dao = new JdbcSingerDao(); dao.setJdbcTemplate(jdbcTemplate()); return dao; } }
NamedParameterJdbcTemplate:
The NamedParameterJdbcTemplate class adds support for programming JDBC statements by using named parameters, as opposed to programming JDBC statements using only classic placeholder ( '?' ) arguments.
public int countOfActorsByFirstName(String firstName) {
String sql = "select count(*) from T_ACTOR where first_name = :first_name";
SqlParameterSource namedParameters = new MapSqlParameterSource("first_name", firstName);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}
//Map-based style
public int countOfActorsByFirstName(String firstName) {
String sql = "select count(*) from T_ACTOR where first_name = :first_name";
Map<String, String> namedParameters = Collections.singletonMap("first_name", firstName);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}
// BeanPropertySqlParameterSource
public int countOfActors(Actor exampleActor) {
String sql = "select count(*) from T_ACTOR where first_name = :firstName and last_name = :lastName";
SqlParameterSource namedParameters = new BeanPropertySqlParameterSource(exampleActor);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class); }
What is a callback
Spring separates the fixed and variable parts of the data-access process into two distinct classes: templates and callbacks.
- Templates manage the fixed of data access
- controlling transactions,
- managing resources, and
- handling exceptions.
- your custom data-access code is handled in callbacks
- creating statements,
- binding parameters, and
- marshaling result sets
A callback is code or reference to a piece of code that is passed as an argument to a method that, at some point during the execution of the methods, will call the code passed as an argument.
Spring converts contents of a ResultSet into domain objects using a callback approach.
What are the three JdbcTemplate callback interfaces that can be used with queries? What is each used for
(You would not have to remember the interface names in the exam, but you should know what they do if you see them in a code sample).
The three callback interfaces that can be used with queries to extract result data are:
-
ResultSetExtractor: processes multiple rows,extractData()returns an object. -
RowCallbackHandler: processes row by row,processRow()is void. Use when no value should be returned. -
Rowmapper: processes row by row,mapRow()returns an object.
Can you execute a plain SQL statement with the JDBC template
Yes. With following methods:
- batchUpdate()
- execute()
- query()
- queryForList()
- queryForObject()
- queryForRowSet()
- update()
DML
DML stands for Data Manipulation Language, the commands SELECT, INSERT, UPDATE, and DELETE are database statements used to create, update, or delete data from existing tables.
DDL DDL stands for Data Definition Language, used to manipulate database objects: tables, views, cursors, etc. DDL database statements can be executed with JdbcTemplate using the execute method.
public int createTable(String name) {
jdbcTemplate.execute("create table " + name + " (id integer, name varchar2)" );
String sql = "select count(*) from " + name;
return jdbcTemplate.queryForObject(sql, Integer.class);
}
When does the JDBC template acquire (and release) a connection - for every method called or once per template? Why
Per method called. A connection is acquired immediately before executing the operation at hand and released immediately after the operation has completed, be it successfully or with an exception thrown.
How does the JdbcTemplate support generic queries? How does it return objects and lists/maps of objects
JdbcTemplate supports querying for any type of object assuming you supplied a RowMapper interface implementation defining the way database table should be mapped to some entity type.
It has many overloaded methods for querying the database but mainly you can divide them in:
query()queryForObject()if you are expecting only one objectqueryForMap()will return a map containing each column value as key(column name)/value(value itself) pairs.queryForList()a list of above if you’re expecting more results
What is a transaction
Transaction: The context of execution for a group of SQL operations is called a transaction. Run them all successfully, or reverted. Tansaction enforces ACID principle:
ACID:
-
Atomicity: It is the main attribute of a transaction. Several operations might be performed over data in any transaction. Those operations must all succeed or commit, or, if something goes wrong, none of them should be persisted; in other words, they all must be rolled back. Atomicity is also known as unit of work.
-
Consistency: For a system to have consistency, at the end of an active transaction the underlying database can never be in an inconsistent state. For example, if order items cannot exist without an order, the system won’t let you add order items without first adding an order.
-
Isolation: Isolation defines how protected your uncommitted data is to other concurrent transactions. Isolation levels range from least protective, which offers access to uncommitted data, to most protective, at which no two transactions work at the same time. Isolation is closely related to concurrency and consistency. If you increase the level of isolation, you get more consistency but lose concurrency—that is, performance. On the other hand, if you decrease the level, your transaction performance increases, but you risk losing consistency.
-
Durability: A system has durability when you receive a successful commit message, and you can be sure that your changes are reflected to the system and will survive any system failure that might occur after that time. Basically, when you commit, your changes are permanent and won’t be lost.
What is the difference between a local and a global transaction
Local transactions:
- resource-specic, your application works with a single database, and your transactions only control DML operations performed on that single database,
- such as a transaction associated with a JDBC connection.
Global transaction:
- means distributed transaction management.
- allows to span multiple transactional resources, typically relational databases and message queues.
- JEE offers JTA to deal with global transactions,
Spring resolves the disadvantages of global and local transactions. It lets application developers use a consistent programming model in any environment.
Is a transaction a cross cutting concern? How is it implemented by Spring
Yes, transaction management is a cross-cutting concern.
AOP is used to decorate beans with transactional behavior. This means that when we annotate classes or methods with @Transactional, a proxy bean will be created to provide the transactional behavior, and it is wrapped around the original bean in an Around advice that takes care of getting a transaction before calling the method and committing the transaction afterward.
AOP proxies use two infrastructure beans for this:
-
TransactionInterceptor -
An implementation of
PlatformTransactionManagerinterface. E.g.,DataSourceTransactionManagerHibernateTransactionManagerJpaTransactionManagerJtaTransactionManagerWebLogicJtaTransactionManager
Under the hood:
An internal infrastructure Spring-specific bean of type InfrastructureAdvisorAutoProxyCreator is registered and acts as a bean postprocessor that modifies the service and repository bean to add transaction-specific logic. Basically, this is the bean that creates the transactional AOP proxy.
When an exception is thrown from within the body of the transactional method, Spring checks the exception type in order to decide if the transaction will commit or rollback.
How are you going to define a transaction in Spring
Two ways of implementing it:
- Declarative, use
@transaction - Programmatic
- Use
TransactionTemplate - Use
PlatformTransactionManager
- Use
Declarative transaction management
Declarative transaction management is non-invasive.
- Configure transaction management support
- Marked a Spring Configuration class using the
@Configuration - Using Java Configuration, define a
PlatformTransactionManagerbean using@bean - Enable transaction management by annotate the config file with
@EnableTransactionManagement
@Configuration @EnableTransactionManagement public class TestDataConfig { @Bean public PlatformTransactionManager txManager(){ return new DataSourceTransactionManager(dataSource()); } } - Marked a Spring Configuration class using the
-
Declare transactional methods using
@Transactional@Service public class UserServiceImpl implements UserService { @Transactional(propagation = Propagation.REQUIRED, readOnly= true) @Override public User findById(Long id) { return userRepo.findById(id); } }
Programmatic transaction management
It is possible to use both declarative and programmatic transaction models simultaneously.
Programmatic transaction management allows you to control transactions through your codeexplicitly starting, committing, and joining them as you see fit.
Spring Framework provides two ways of implemeting Programmatic Transaction:
- Using
TransactionTemplate, which is recommended by Spring; - Using
PlatformTransactionManagerdirectly, which is low level.
Using TransactionTemplate
It uses a callback approach.
-
can write a
TransactionCallbackimplementation, runexecute(..)public class SimpleService implements Service { // single TransactionTemplate shared amongst all methods in this instance private final TransactionTemplate transactionTemplate; // use constructor-injection to supply the PlatformTransactionManager public SimpleService(PlatformTransactionManager transactionManager) { this.transactionTemplate = new TransactionTemplate(transactionManager); } public Object someServiceMethod() { return transactionTemplate.execute(new TransactionCallback() { // the code in this method executes in a transactional context public Object doInTransaction(TransactionStatus status) { updateOperation1(); return resultOfUpdateOperation2(); } }); } } -
If there is no return value, use
TransactionCallbackWithoutResulttransactionTemplate.execute(new TransactionCallbackWithoutResult() { protected void doInTransactionWithoutResult(TransactionStatus status) { updateOperation1(); updateOperation2(); } }); -
NB. Code within the callback can roll the transaction back by calling the
setRollbackOnly()method on the suppliedTransactionStatusobjecttransactionTemplate.execute(new TransactionCallbackWithoutResult() { protected void doInTransactionWithoutResult(TransactionStatus status) { try { updateOperation1(); updateOperation2(); } catch ( SomeBusinessException ex) { status.setRollbackOnly(); } } });
Using PlatformTransactionManager
- First, pass the implementation of the
PlatformTransactionManageryou use to your bean through a bean reference. - Then, by using the
TransactionDefinitionandTransactionStatusobjects, you can initiate transactions, roll back, and commit.
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
// explicitly setting the transaction name is something that can be done only programmatically
def.setName("SomeTxName");
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = txManager.getTransaction(def);
try {
// execute your business logic here
} catch (MyException ex) {
txManager.rollback(status);
throw ex;
}
txManager.commit(status);
What does @Transactional do
@Transactional is metadata that specifies that an interface, class, or method must have transactional semantics.
@Transactional Settings
-
The transactionManager attribute value defines the transaction manager used to manage the transaction in the context of which the annotated method is executed
-
The readOnly attribute should be used for transactions that involve operations that do not modify the database (example: searching, counting records). Defalt FALSE.
-
The propagation attribute can be used to define behavior of the target methods: if they should be executed in an existing or new transaction, or no transaction at all. There are seven propagation types. Default: PROPAGATION_REQUIRED.
-
The isolation attribute value defines how data modified in a transaction affects other simultaneous transactions. As a general idea, transactions should be isolated. A transaction should not be able to access changes from another uncommitted transaction. There are four levels of isolation, but every database management system supports them differently. In Spring, there are five isolation values. DEFAULT: the default isolation level of the DBMS.
-
timeout. By default, the value of this attribute is defined by the transaction manager provider, but it can be changed by setting a different value in the annotation:
@Transactional(timeout=3600)by milliseconds. -
rollbackFor. When this type of exception is thrown during the execution of a transactional method, the transaction is rolled back. By default, i’s rolled back only when a RuntimeException or Errors is thrown. In using this attribute, the rollback can be triggered for checked exceptions as well.
-
noRollbackFor attribute values should be one or more exception classes, subclasses of Throwable. When this type of exception is thrown during the execution of a transactional method, the transaction is not rolled back. By default, a transaction is rolled back only when a RuntimeException is thrown. Using this attribute, rollback of a transaction can be avoided for a RuntimeException as well.
Default settings for @Transactional:
- Propagation setting is
PROPAGATION_REQUIRED. - Isolation level is
ISOLATION_DEFAULT. - Transaction is
read/write, which isread only = FALSE. - Transaction timeout defaults to the default timeout of the underlying transaction system, or to none if timeouts are not supported.
- Any RuntimeException triggers rollback, and any checked Exception does not.
Annotation driven transaction settings:
mode- The default mode (proxy) processes annotated beans to be proxied by using Spring’s AOP framework.
- The alternative mode (aspectj) instead weaves the affected classes with Spring’s AspectJ transaction aspect, modifying the target class byte code to apply to any kind of method call. AspectJ weaving requires
spring-aspects.jarin the classpath as well as having load-time weaving (or compiletime weaving) enabled.
proxyTargetClas- Applies to proxy mode only.
- If it’s false or omitted, then standard JDK interface-based proxies are created.
- If the proxy-target-class attribute is set to true, class-based proxies are created.
order- Defines the order of the transaction advice that is applied to beans annotated with
@Transactional - Default
Ordered.LOWEST_PRECEDE NCE.
- Defines the order of the transaction advice that is applied to beans annotated with
What is the PlatformTransactionManager
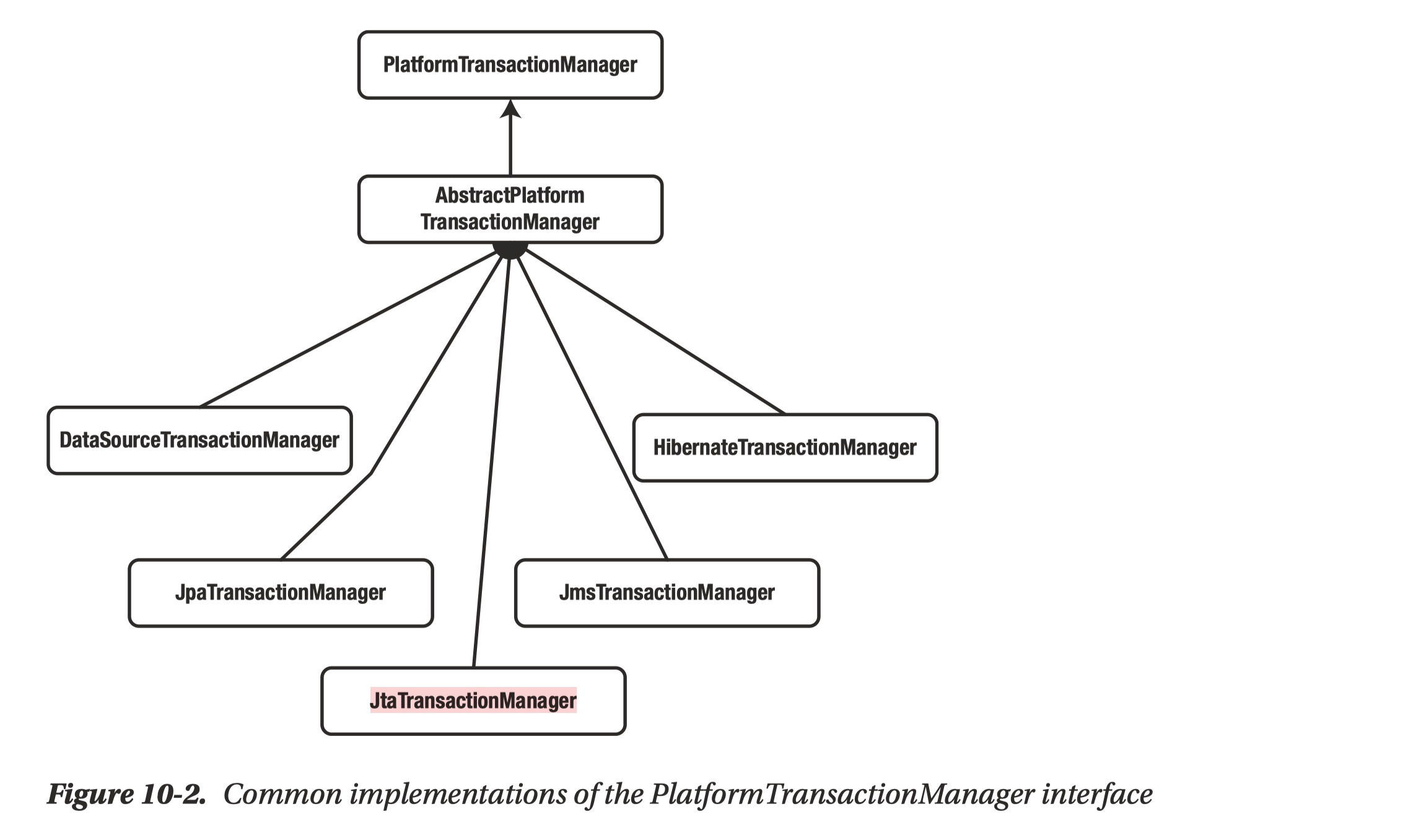
Spring’s core transaction management abstraction is based on the interface PlatformTransactionManager.
It uses the TransactionDefinition and TransactionStatus interfaces to create and manage transactions.
A transaction manager is needed no matter which transaction management strategy (programmatic or declarative) you choose.
Public interface PlatformTransactionManager(){
TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException;
Void commit(TransactionStatus status) throws TransactionException;
Void rollback(TransactionStatus status) throws TransactionException;
}
The PlatformTransactionManager interface provides three methods for working with transactions:
getTransaction(): takes aTransactionDefinitioninterface as an argument and returns aTransactionStatusinterface.-
TransactionDefinitioninterfaceThe
TransactionDefinitioninterface controls the properties of a transaction. It specifies:- Propagation
- Isolation
- Timeout
- Read-only status
public interface TransactionDefinition { // Variable declaration statements omitted ... int getPropagationBehavior(); int getIsolationLevel(); int getTimeout(); boolean isReadOnly(); String getName(); } -
TransactionStatusinterfaceThe returned TransactionStatus is used to control the transaction execution. The code can check whether the transaction is a new one or whether it is a read-only transaction, and it can initiate a rollback.
setRollbackOnly()causes a rollback and ends the active transaction.public interface TransactionStatus extends SavepointManager { boolean isNewTransaction(); boolean hasSavepoint(); void setRollbackOnly(); boolean isRollbackOnly(); void flush(); boolean isCompleted(); }
-
-
commit(): Commit the given transaction, with regard to its status rollback: Perform a rollback of the given transaction
Implementations of PlatformTransactionManager interface. E.g.,
DataSourceTransactionManager: Suitable if you are only using JDBCHibernateTransactionManager- Hibernate without JPA
- Also possible to use JDBC at the same time
JpaTransactionManager:- Suitable if you are using JPA.
- Also possible to use JDBC at the same time
JdoTransactionManage- using JDO
- Also possible to use JDBC at the same time
JtaTransactionManager- Suitable if you are using global transactions—that is, the distributed transaction management capability of your application server.
- You can use any data access technology
WebLogicJtaTransactionManager- etc.
You typically define PlatformTransactionManager implementation through dependency injection.
Examples:
-
Deal with only a single data source in your application and access it with JDBC, use
DataSourceTransactionManager@Bean public DataSource dataSource() { DriverManagerDataSource dataSource = new DriverManagerDataSource(); dataSource.setDriverClassName("org.h2.Driver"); dataSource.setUrl("jdbc:h2:tcp://localhost/~/test"); dataSource.setUsername("sa"); dataSource.setPassword(""); return dataSource; } @Bean public DataSourceTransactionManager transactionManager() { DataSourceTransactionManager transactionManager = new DataSourceTransactionManager(); transactionManager.setDataSource(dataSource()); return transactionManager; } -
If you are using an object-relational mapping framework to access a database, you should choose a corresponding transaction manager for this framework, such as
HibernateTransactionManagerorJpaTransactionManager.@Bean public PlatformTransactionManager transactionManager() { JpaTransactionManager transactionManager = new JpaTransactionManager(); transactionManager.setDataSource(dataSource()); return transactionManager; } -
If you are using JTA for transaction management on a Java EE application server, you should use JtaTransactionManager to look up a transaction from the application server. Additionally, JtaTransactionManager is appropriate for distributed transactions (transactions that span multiple resources). Note that while it’s common to use a JTA transaction manager to integrate the application server’s transaction manager, there’s nothing stopping you from using a stand-alone JTA transaction manager such as Atomikos.
Is the JDBC template able to participate in an existing transaction
Yes, both declarative and programmatic ways, by wrapping the DataSource using a TransactionAwareDataSourceProxy.
This is a proxy for a target DataSource, which wraps the target DataSource to add awareness of Spring-managed transactions.
What is a transaction isolation level? How many do we have and how are they ordered
Transaction Isolation is the isolation of one transactions from another. It anwsers the question: are transactions affect each other?
In Spring, there are five isolation values that are defined in the Isolation enum:
-
Isolation.DEFAULT: DB default -
Isolation.READ_UNCOMMITTED: It allows this transaction to see data modified by other uncommitted transactions. Dirty reads, NonRepeatable Read and Phantom Read. -
Isolation.READ_COMMITTED: Default for most dbs. It ensures that other transactions are not able to read data that has not been committed by other transactions. However, the data that was read by one transaction can be updated by other transactions. NonRepeatable Read and Phantom Read. -
Isolation.REPEATABLE_READ: Ensures that once you select data, you can select at least the same set again. However, if other transactions insert new data, you can still select the newly inserted data. Phantom Read. -
Isolation.SERIALIZABLE: most restrictive, read and write locks.
Higher isolation levels is a reduction of the ability of multiple users and systems concurrently accessing to the resources.
What is @EnableTransactionManagement for
Both @EnableTransactionManagement and <tx:annotation-driven ../> enable all infrastructure beans necessary for supporting transactional execution.
Components registered when the @EnableTransactionManagement annotation is used are:
- A TransactionInterceptor: calls to @Transactional methods
- A JDK Proxy or AspectJ advice, intercepts methods annotated with
@Transactional
@EnableTransactionManagement and <tx:annotation-driven/> only looks for @Transactional on beans in the same application context they are defined in. This means that, if you put annotation driven configuration in a WebApplicationContext for a DispatcherServlet it only checks for @Transactional beans in your controllers, and not your services.
What does transaction propagation mean
It is to define behavior of the target methods: if they should be executed in an existing or new transaction, or no transaction at all.
Spring Propagation enum:
Propagation.REQUIRED:@Transactional(propagation = Propagation.REQUIRED)- Starts a new transaction if there is no transaction.
- An existing transaction is kept and the second method call is executed within the same transaction.
- If the second method throws an exception that causes rollback, the whole transaction rolls back. It doesn’t matter if the first transaction handles that exception or not.
- Transaction rolls back and throws
UnexpectedRollbackException.
Propagation.REQUIRES_NEW:- always starts a new transaction regardless of whether there is already an active one.
Propagation.NESTED.- there is only one active transaction that spans method calls.
- only available if your persistence technology is JDBC.
- it won’t work if you are using JPA or Hibernate.
JDBC savepointsare used to mark new method calls. When an exception occurs in the second method, the transaction until the last savepoint is rolled back
Propagation.MANDATORY.- An error occurs if there is not an active transaction.
Propagation.NEVER.- An error occurs if there is an active transaction in the system when the method is called.
Propagation.NOT_SUPPORTED:- If there is an active transaction when the method is called, the active transaction is suspended until the end of the method call.
Propagation.SUPPORTS.- current method work in a transaction if one already exists.
- Otherwise, the method will work without any transaction.
@Service
public class UserServiceImpl implements UserService {
@Transactional(propagation = Propagation.REQUIRED, readOnly= true)
@Override public User findById(Long id) {
return userRepo.findById(id);
}
}
What happens if one @Transactional annotated method is calling another @Transactional annotated method on the same object instance
As per the limitation of Spring AOP, a self-invocation of a proxied Spring Bean effectively bypasses the proxy, thus the second method will be excuted in the same transaction with the first.
Service layer or Repository layer
Use @Transactional in the service layer or the DAO/ repository layer, but not both.
The service layer is the usual choice, because service methods call multiple repository methods that need to be executed in the same transaction.
The only reason to make your repositories transactional is if you do not need a service layer at all, which is usually the case for small educational applications.
Where can the @Transactional annotation be used? What is a typical usage if you put it at class level
Class level:
- default for all methods of the declaring class
- method level transactional can override some attributes
- its subclasses
- does not apply to ancestor classes up the class hierarchy
Method level:
- Only Public method
- protected, private or package-visible methods with the @Transactional annotation, no error is raised, but the annotated method does not exhibit the congured transactional settings.
- If you need to annotate non-public methods, consider using AspectJ
Interface:
- this works only as you would expect it to if you use interface-based proxies
- recommends that you annotate only concrete classes and methods
What does declarative transaction management mean
For declarative transaction management:
- It keeps transaction management out of business logic.
- Easy to configure. Use Java annotations or XML configuration files.
Basically, when those specified methods are called, Spring begins a new transaction, and when the method returns without any exception it commits the transaction; otherwise, it rolls back. Hence, you don’t have to write a single line of transaction demarcation code in your method bodies.
How It Works:
-
The
@EnableTransactionManagementannotation activates annotation‐based declarative transaction management. -
Spring Container scans managed beans’ classes for the
@Transactionalannotation. -
When the annotation is found, it creates a proxy that wraps your actual bean instance.
-
From now on, that proxy instance becomes your bean, and it’s delivered from Spring Container when requested.
Programmatic transaction management is a good idea only if:
- Has only a small number of transactional operations. For example, if you have a web application that requires transactions only for certain update operations, you may not want to set up transactional proxies by using Spring or any other technology.
- Being able to set the transaction name explicitly.
What is the default rollback policy? How can you override it
- Default rollback policy: only when a
RuntimeExceptionis thrown. - Override it by using
rollbackForornoRollbackFor. - E.g., use
rollbackForrollback can be triggered for checked exceptions as well.
@Transactional(rollbackFor = MailSendingException.class)
public int updatePassword(Long userId, String newPass) throws MailSendingException {
User u = userRepo.findById(userId);
String email = u.getEmail();
sendEmail(email);
return userRepo.updatePassword(userId, newPass);
}
What is the default rollback policy in a JUnit test
When you use the @RunWith(SpringJUnit4ClassRunner.class) in JUnit 4 or @ExtendWith(SpringExtension.class) in JUnit 5, and annotate your @Test annotated method with @Transactional?
- Test-methods will be executed in a transaction, and will roll back after completion.
- The rollback policy of a test can be changed using the
@Rollbackset to false,@Rollback(false) @Commitindicates that the transaction for a transactional test method should be committed after the test method has completed. You can use @Commit as a direct replacement for @Rollback(false) to more explicitly convey the intent of the code. Analogous to @Rollback, @Commit can also be declared as a class-level or method-level annotation.
The @DataJpaTest tests are transactional and rolled back at the end of each test by default. You can disable this default rollback behavior for a single test or for an entire test class by annotating with @Transactional(propagation = Propagation.NOT_SUPPORTED).
Why is the term “unit of work” so important and why does JDBC AutoCommit violate this pattern
- The unit of work describes the atomicity of transactions.
- JDBC AutoCommit will cause each individual SQL statement as to be executed in its own transaction, which makes it impossible to perform operations that consist of multiple SQL statements as a unit of work.
- JDBC AutoCommit can be disabled by calling the
setAutoCommit()to false on a JDBC connection.
What does JPA stand for - what about ORM
JPA: Java Persistence API. JPA is a POJO-based persistence mechanism that draws ideas from both Hibernate and Java Data Objects (JDO) and mixes Java 5 annotations in for good measure.
ORM: Object-Relational Mapping. Mappingg a java entity to SQL database table.
Benefits of using Spring’s JPA support in your data access layer:
- Easier and more powerful persistence unit configuration
- Automatic EntityManager management
- Easier testing
- Common data access exceptions
- Integrated transaction management
The first step toward using JPA with Spring is to configure an entity manager factory as a bean in the Spring application context. JPA-based applications use an implementation of EntityManagerFactory to get an instance of an EntityManager. The JPA specification defines two kinds of entity managers:
- Application-managed
- the application is responsible for opening or closing entity managers and involving the entity manager in transactions.
- most appropriate for use in standalone applications that don’t run in a Java EE container.
EntityManagersare created by anEntityManagerFactoryobtained by calling thecreateEntityManagerFactory()method of the PersistenceProvider.- If you’re using an application-managed entity manager, Spring plays the role of an application and transparently deals with the EntityManager on your behalf.
LocalEntityManagerFactoryBeanproduces an application-managedEntityManagerFactory.- Application-managed entity-manager factories derive most of their configuration information from a configuration file called
persistence.xml. This file must appear in theMETA-INFdirectory in the classpath. The purpose of thepersistence.xmlfile is to define one or more persistence units.
@Bean public LocalEntityManagerFactoryBean entityManagerFactoryBean() { LocalEntityManagerFactoryBean emfb = new LocalEntityManagerFactoryBean(); emfb.setPersistenceUnitName("demo"); return emfb; } - Container-managed
- Entity managers are created and managed by a Java EE container.
- The application doesn’t interact with the entity manager factory at all.
- Instead, entity managers are obtained directly through injection or from JNDI.
- The container is responsible for configuring the entity manager factories.
- most appropriate for use by a Java EE container that wants to maintain some control over JPA configuration beyond what’s specified in
persistence.xml. EntityManagerFactorysare obtained through PersistenceProvider’screateContainerEntityManagerFactory()method.- Spring plays the role of the container.
LocalContainerEntityManagerFactoryBeanproduces a container-managedEntityManagerFactory.- Instead of configuring data-source details in persistence.xml, you can configure this information in the Spring application context.
- JPA has two annotations to obtain container‐managed
EntityManagerFactoryorEntityManagerinstances within Java EE environments.- The
@PersistenceUnitannotation expresses a dependency on anEntityManagerFactory, and @PersistenceContextexpresses a dependency on a containermanagedEntityManagerinstance.
- The
@Bean public LocalContainerEntityManagerFactoryBean entityManagerFactory( DataSource dataSource, JpaVendorAdapter jpaVendorAdapter) { LocalContainerEntityManagerFactoryBean emfb = new LocalContainerEntityManagerFactoryBean(); emfb.setDataSource(dataSource); emfb.setJpaVendorAdapter(jpaVendorAdapter); return emfb; }
What is the idea behind an ORM? What are benefits/disadvantages or ORM
Idea: Developers only work on objects and no need to care about how to maintain the relationship and how they persist.
ORM Duties:
- Data type convertion
- Maintaining relations between objects
- JAP Query language to handle vendor spedific SQL
Benefits:
- Easier testing. It’s easier to test each piece of persistence-related code in isolation.
- Common data access exceptions. In
DataAccessExceptionhierarchy. - General resource management. Spring offers effcient, easy, and safe handling of persistence resources. E.g., Spring makes it easy to create and bind a Session to the current thread transparently, by exposing a current Session through the Hibernate SessionFactory .
- Integrated transaction management. Declarative, aspect-oriented programming (AOP) style method interceptor.
- Keep track of changes
- Reduce code (and develop time)
- Lazy loading. As object graphs become more complex, you sometimes don’t want to fetch entire relationships immediately.
- Eager fetching. Eager fetching allows you to grab an entire object graph in one query.
- Cascading. Sometimes changes to a database table should result in changes to other tables as well
- Save you literally thousands of lines of code and hours of development time.
- Lets you switch your focus from writing error-prone SQL code to addressing your application’s requirements.
Disadvantage:
- Generated SQL Query low performance
- Complexity, requires more knowledge
- Deal with legacy database is difficult
What is a PersistenceContext and what is an EntityManager. What is the relationship between both
JPA has two annotations to obtain container‐managed EntityManagerFactory or EntityManager instances within Java EE environments.
- The
@PersistenceUnitannotation expresses a dependency on anEntityManagerFactory, and @PersistenceContextexpresses a dependency on a containermanagedEntityManagerinstance.
@PersistenceUnit and @PersistenceContext
- They aren’t Spring annotations; they’re provided by the JPA specification.
- Both annotations can be used at either the field or method level.
- Visibility of those fields and methods doesn’t matter.
-
Spring’s
PersistenceAnnotationBeanPostProcessormust be configured explicitly:@Bean public PersistenceAnnotationBeanPostProcessor paPostProcessor() { return new PersistenceAnnotationBeanPostProcessor(); } -
if you do use Spring’s exception translation
@Bean public BeanPostProcessor persistenceTranslation() { return new PersistenceExceptionTranslationPostProcessor(); }
@PersistenceContext
- Used for entity manager injection.
- Expresses a dependency on a container-managed EntityManager and its associated persistence context.
- This field does not need to be autowired, since this annotation is picked up by an infrastructure Spring bean postprocessor bean that makes sure to create and inject an EntityManager instance.
- @PersistenceContext has a type attribute
PersistenceContextType.TRANSACTIONIn stateless beans, like singleton bean, it is safe to use only the PersistenceContextType.TRANSACTION value for a shared EntityManager to be created and injected into for the current activePersistenceContextType.EXTENDED- is purposefully designed to support beans, like stateful EJBs, session Spring beans, or request‐scoped Spring beans. The shared EntityManager instance wouldn’t be bound to the active transaction and might span more than one transaction.
PersistenceContext It’s essentially a Cache, containing a set of domain objects/entities in which for every persistent entity there is a unique entity instance.
- Default persistence context duration is one single transaction
- Can be configured
- the persistence context itself is managed by EntityManager
Persistence Unit:
a group of entity classes defined by the developer to map database records to objects that are managed by an Entity Manager, basically all classes annotated with @Entity, @MappedSuperclass, and @Embedded in an application.
- All entity classes must define a primary key, must have a non-arg constructor or not allowed to be final.
- This set of entity classes represents data contained in a single datasource.
- Multiple persistence units can be defined within the same application.
- Configuration of persistence units can be done using XML, e.g.,
persistence.xmlfile under theMETA-INFdirectory. JPA no need to specify it.
EntityManager represents a PersistenceContext. The entity manager provides an API for managing a persistence context and interacting with the entities in the persistence context.
- It does creation, update, querying, deletion.
- An EntityManager isn’t thread-safe and generally shouldn’t be injected into a shared singleton bean like your repository.
@PersistenceContextdoesn’t inject an EntityManager—at least, not exactly. Instead of giving the repository a real EntityManager, it gives a proxy to a real EntityManager. That real EntityManager either is one associated with the current transaction or, if one doesn’t exist, creates a new one.
EntityManagerFactory
It has the responsibility of creating application-managed Entity Manager instances and therefore a PersistenceContext/Cache. Thread safe, shareable, represent a single datasource and persistence context.
@Repository
public class JpaUserRepo implements UserRepo {
private EntityManager entityManager;
@PersistenceContext
void setEntityManager(EntityManager entityManager) {
this.entityManager = entityManager;
}
}
What do you need to do in Spring if you would like to work with JPA
-
Declare dependencies: ORM dependency, db driver dependency, transaction manager dependency.
@Entityclasses- is part of the javax.persistence.*, not JPA!
@Entitymarks classes as templates for domain objects, also called entities to database tables.- The
@Entityannotation can be applied only at class level. @Entityare mapped to database tables matching the class name, unless specified otherwise using the@Tableannotation.@Entityand@Idare mandatory for a domain class.
- Define an EntityManagerFactory bean.
- Simplest:
LocalEntityManagerFactoryBean. It produces an application-managed EntityManagerFactory. - Obtain an
EntityManagerFactoryusing JNDI, use when app ran in Java EE server - Full JPA capabilities:
LocalContainerEntityManagerFactoryBean
- Simplest:
-
Define a
DataSourcebean -
Define a
TransactionManagerbean - Implement repositories
@Configuration
@EnableJpaRepositories
@EnableTransactionManagement
class ApplicationConfig {
@Bean
public DataSource dataSource() {
EmbeddedDatabaseBuilder builder = new EmbeddedDatabaseBuilder();
return builder.setType(EmbeddedDatabaseType.HSQL).build();
}
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactory() {
HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();
vendorAdapter.setGenerateDdl(true);
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(vendorAdapter);
factory.setPackagesToScan("com.acme.domain");
factory.setDataSource(dataSource());
return factory;
}
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
You must create LocalContainerEntityManagerFactoryBean and not EntityManagerFactory directly, since the former also participates in exception translation mechanisms in addition to creating EntityManagerFactory .
Are you able to participate in a given transaction in Spring while working with JPA
Yes you can.
The Spring JpaTransactionManager supports direct DataSource access within one and the same transaction allowing for mixing plain JDBC code that is unaware of JPA with code that use JPA.
If the Spring application is to be deployed to a JavaEE server, then JtaTransactionManager can be used in the Spring application.
Which PlatformTransactionManager(s) can you use with JPA
Implementations of PlatformTransactionManager interface. E.g.,
-
DataSourceTransactionManager: Suitable if you are only using JDBC HibernateTransactionManager- Hibernate without JPA
- Also possible to use JDBC at the same time
JpaTransactionManager:- Suitable if you are using JPA.
- Also possible to use JDBC at the same time
JdoTransactionManage- using JDO
- Also possible to use JDBC at the same time
JtaTransactionManager- Suitable if you are using global transactions—that is, the distributed transaction management capability of your application server.
- You can use any data access technology
-
WebLogicJtaTransactionManager - etc.
JtaTransactionManager is used for global transactions, so that they can span multiple resources such as databases, queues etc. If the application has multiple JPA entity manager factories that are to be transactional, then a JTA transaction manager is required.
When using JPA with one single entity manager factory, the Spring Framework JpaTransactionManager is the recommended choice. This is also the only transaction manager that is JPA entity manager factory aware.
What does @PersistenceContext do
@PersistenceContext
- Used for entity manager injection.
- Expresses a dependency on a container-managed EntityManager and its associated persistence context.
- This field does not need to be autowired, since this annotation is picked up by an infrastructure Spring bean postprocessor bean that makes sure to create and inject an EntityManager instance.
- @PersistenceContext has a type attribute
- PersistenceContextType.TRANSACTION In stateless beans, like singleton bean, it is safe to use only the PersistenceContextType.TRANSACTION value for a shared EntityManager to be created and injected into for the current active
- PersistenceContextType.EXTENDED
- is purposefully designed to support beans, like stateful EJBs, session Spring beans, or request‐scoped Spring beans. The shared EntityManager instance wouldn’t be bound to the active transaction and might span more than one transaction.
PersistenceContext It’s essentially a Cache, containing a set of domain objects/entities in which for every persistent entity there is a unique entity instance.
- Default persistence context duration is one single transaction
- Can be configured
- the persistence context itself is managed by EntityManager
What do you have to configure to use JPA with Spring? How does Spring Boot make this easier
see: What do you need to do in Spring if you would like to work with JPA?
To use Spring Data components in a JPA project, a dependency on the package spring-data-jpa must be introduced.
JPA in SpringBoot
- SpringBoot provides a default set fo dependencies needed for JPA in starter.
- Provides all default Spring beans needed to use JPA.
- Provides a number of default properties related to persistence and JPA.
Disable Spring Data Auto Configuration in SpringBoot:
It’s useful in testing.
-
Disable Using Annotation
@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class, DataSourceTransactionManagerAutoConfiguration.class, HibernateJpaAutoConfiguration.class}) -
Disable Using Property File
spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration,
org.springframework.boot.autoconfigure.orm.jpa.HibernateJpaAutoConfiguration,
org.springframework.boot.autoconfigure.jdbc.DataSourceTransactionManagerAutoConfiguration
What is a Repository interface
A Spring Data repository is also known as a “instant” repository, because they can be created instantly by extending one of the Spring-specialized interfaces.
When a custom repository interface extends JpaRepository, it will automatically be enriched with functionality to save entities, search them by ID, retrieve all of them from the database, delete entities, flush, etc.
By default, repositories are instantiated eagerly unless explicitly annotated with @Lazy. LAZY is a decent choice for testing scenarios.
How do you define an “instant” repository? Why is it an interface not a class
Under the hood, Spring creates a proxy object that is a fullly functioning repository bean. The repository implementation is generated at application startup time, as the Spring application context is being created.
Any additional functionality that is not provided by default can be easily implemented by defining a method skeleton and providing the desired functionality using annotations. It’s including an implementation of all 18 methods inherited from
- JpaRepository,
- PagingAndSortingRepository, and
- CrudRepository.
JDBC Support typical JDBC support. You could have the DataSource injected into an initialization method, where you would create a JdbcTemplate and other data access support classes
@Repository
public class JdbcMovieFinder implements MovieFinder {
private JdbcTemplate jdbcTemplate;
@Autowired
public void init(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
}
JPA repository JPA-based repository needs access to an EntityManager.
@Repository
public class JpaMovieFinder implements MovieFinder {
@PersistenceContext
private EntityManager entityManager;
}
classic Hibernate APIs inject SessionFactory
@Repository
public class HibernateMovieFinder implements MovieFinder {
private SessionFactory sessionFactory;
@Autowired
public void setSessionFactory(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
}
What is the naming convention for finder methods

- verbs in the method name: get, read, find, query,stream and count.
-
prefixes findalso can be replaced with readget query stream private static final String QUERY_PATTERN = "find|read|get|query|stream"; - findAllByXxx()
arefindByXxx()` identical. - The
countverb, on the other hand, returns a count of matching objects, rather than the objects themselves.
-
- The subject of a repository method is optional.
readSpittersByFirstnameOrLastname()=readByFirstnameOrLastname()readPuppiesByFirstnameOrLastname()=readThoseThingsWeWantByFirstnameOrLastname()- They’re all requal! Beccause the type of object being retrieved is determined by how you parameterize the JpaRepository interface, not the subject of the method name.
- There is one exception to the subject being ignored. If the subject starts with the word
Distinct, then the generated query will be written to ensure a distinct result set.
- The
predicatespecifies the properties that will constrain the result set.- Each condition must reference a property and may also specify a comparison operation.
- If the comparison operator is left off, it’s implied to be an equals operation.
- You may choose any other comparison operations,
- When dealing with
Stringproperties, the condition may also includeIgnoringCaseorIgnoresCase. - you may also use
AllIgnoringCaseorAllIgnoresCaseafter all the conditions to ignore case for all conditions - conditional parts are separated by either
AndorOr
- Limiting Query Results
- The results of query methods can be limited by using the
firstortopkeywords - An optional numeric value can be appended to top or first to specify the maximum result size to be returned.
- If the number is left out, a result size of 1 is assumed.
User findFirstByOrderByLastnameAsc(); User findTopByOrderByAgeDesc(); Page<User> queryFirst10ByLastname(String lastname, Pageable pageable); Slice<User> findTop3ByLastname(String lastname, Pageable pageable); List<User> findFirst10ByLastname(String lastname, Sort sort); List<User> findTop10ByLastname(String lastname, Pageable pageable); - The results of query methods can be limited by using the
How are Spring Data repositories implemented by Spring at runtime
For a Spring Data repository a JDK dynamic proxy is created which intercepts all calls to the repository.
The default behavior is to route calls to the default repository implementation, which in Spring Data JPA is the SimpleJpaRepository class.
What is @Query used for
@Query allows for specifying a query to be used with a Spring Data JPA repository method.
When the name of the named parameter is the same as the name of the argument in the method annotated with @Query, the @Param annoation is not needed.
But if the method argument has a different name, the @Param annotation is needed to tell Spring that the value of this argument is to be injected in the named parameter in the query.
Queries annotated to the query method take precedence over queries defined using @NamedQuery or named queries declared in orm.xml .
Annotation-based configuration has the advantage of not needing another cofiguration file to be edited, lowering maintenance effort.
public interface UserRepo extends JpaRepository<User, Long> {
@Query("select u from User u where u.username like %?1%")
List<User> findAllByUserName(String username);
// using named parameters
@Query("select u from User u where u.username= :un")
User findOneByUsername(@Param("un") String username);
@Query("select u.username from User u where u.id= :id")
String findUsernameById(Long id);
@Query("select count(u) from User u")
long countUsers();
}
Named queries are part of the metadata, and are defined with the annotation @NamedQuery, The annotation @NamedQueries can be used to group multiple queries together.
@Entity
@Table(name="P_USER")
@SequenceGenerator(name = "seqGen", allocationSize = 1) @NamedQueries({
@NamedQuery(name=User.FIND_BY_USERNAME_EXACT, query = "from User u where username= ?"), @NamedQuery(name=User.FIND_BY_USERNAME_LIKE, query = "from User u where username like ?")
})
public class User extends AbstractEntity { }
native queries
The @Query annotation allows for running native queries by setting the nativeQuery flag to true (nativeQuery = true), as shown in the following example:
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT * FROM USERS WHERE EMAIL_ADDRESS = ?1", nativeQuery = true)
User findByEmailAddress(String emailAddress);
}
- Spring Data JPA does not currently support dynamic sorting for native queries,
- You can, however, use native queries for pagination by specifying the count query yourself.
References
- Spring Framework Reference - Data Access
- Spring Data JPA - Reference Documentation
- Core Spring 5 Certification in Detail by Ivan Krizsan
- Pivotal Certified Professional Spring Developer Exam Study Guide
- Beginning Spring
- Spring in Action, Fifth Edition
- Pro Spring 5: An In-Depth Guide to the Spring Framework and Its Tools